
Introduction
An important long-term trend of machine learning and AI is the growing sophistication and power of software frameworks for creating machine learning and AI models and applications. They are a variety of software frameworks that have been developed and refined over the years that have been developed for different types of users and for different purposes. This trend applies to all areas of software development, from web applications to mobile applications to data center applications.
Of course, there is still a need for software developers, data scientists and data engineers, but the appropriate software framework opens up the development of models and applications to a broader community. Below we will look at several different types of software frameworks, including visual programming frameworks, low code data science applications, and no code data machine learning applications.
Low Code Data Science
Low code data science has been around for over 20 years and enables a wider variety of data scientists to build and deploy data science applications. Low code data science uses visual programming so that you can copy, paste and drag icons for extracting data from data sources, cleaning data, building features, training models, validating models, and deploying models into certain applications.
Low code data science still requires understanding the basics of data science, including the roles of cleaning, extracting, transforming data, building features, training models, validating models, etc. Low code data science opens up these techniques to data scientists who understand these tasks but may not have the programming expertise to use programming languages, such as Python or R effectively.
Low code data science views data science as a workflow or pipeline and allows you to drag, drop and connect visual elements, each representing a particular task. You can also introduce your own custom tasks by writing your code, which can then be used like the predefined tasks.
Visual programming itself, an important element of low code data science, has been around in its current incarnation since the early 1990’s. The Wikipedia period article on visual programming has links to dozens of visual programming tools, including a category of tools for data warehousing / business intelligence. It is important to note that many data science visual programming tools are listed in the that the list is not complete and important tools such KNIME are listed in the systems/simulation list, not the data warehousing / business intelligence list.
No Code Data Science
There is a spectrum, and, as just mentioned, no-code data science is still designed for data scientists. No code data science (or no code machine learning / AI) is designed for a broader range of users. With no code machine learning, you just need some data. In general, no code AI/ML is designed so that the user just needs to select the appropriate data and, perhaps, the targeted application where the model should be deployed [1].
No code AI/ML makes use of default parameters, while low code AI/ML allow the data scientist to tune the default parameters of task (represented by a visual icon) if desired.
Using No Code AI/ML to Develop a “First Look”
An important role of no code AI/ML applications is to try out new ideas quickly with very little labor. You might call this a “first look” at a new concept or idea. You can also think of this as the stage before a proof of concept (POC) or a pre-proof of concept (Pre-POC). If the idea demonstrated with no code AI/ML looks interesting, with additional work it can be turned into proof of concept, follow by followed by a prototype, pilot and MVP.
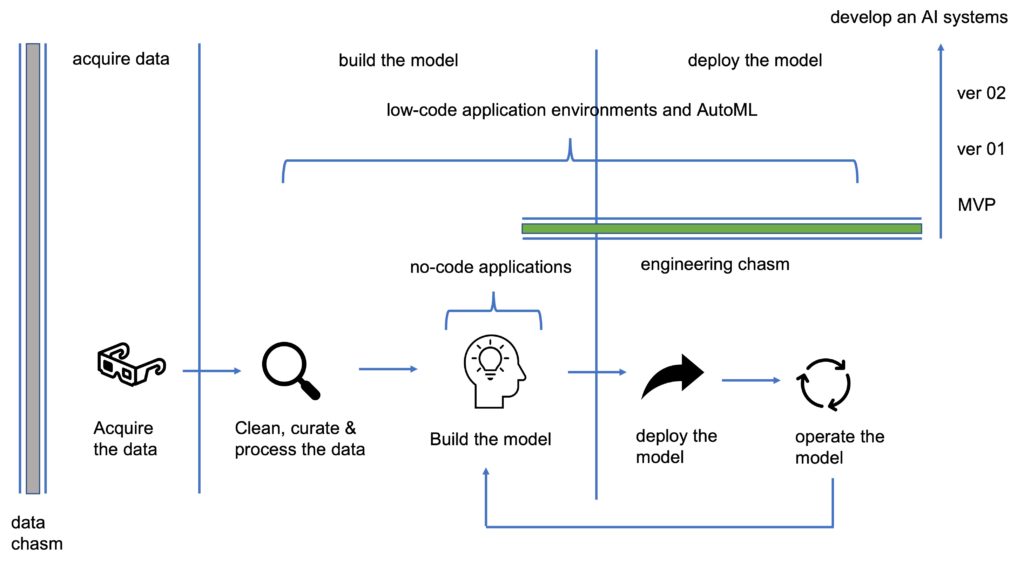
Crossing the Data and Engineering Chasms
To move from a first look or Pre-POC to a MVP, two barriers must be crossed. See Figure 1.
The first barrier is the data chasm (see Chapter 6 of my Primer [2]). This is the challenge of getting all the data that you need and labeling it appropriately so that you can build not just a ML/AI model, but an AI/ML model that generates the required business or operational value. This is usually a significant effort, especially given the fact that datasets large enough to be used for deep learning and AI usually have significant biases, gaps, and other defects that must be removed before a viable MVP can be developed.
The second barrier is the engineering chasm, which is described in my February 2021 post [3]. This is the challenge of moving from a ML/AI model (that has crossed the data chasm) to a ML/AI system that satisfies user requirements and generate sufficient revenue or value to the company or organization to operate and sustain the system.
The challenge is developing effective methods for crossing the data and engineering chasms and moving from ideas to POCs, prototypes, pilots, and MVPs. If you have an effective framework for moving from ML/AI POCs to ML/AI MVPs, adding no-code to support Pre-POCs is easy.
What about your Competitors?
From an analytic strategy point of view and a competitive landscape perspective, it is important to understand what your competitors are doing. In most cases, you should assume that your adversaries and competitors are using no-code and low-code approaches to explore new applications. By including no-code ML/AI as one of the technologies you use, you provide the ability to take a quick look at new ideas and concepts to a wider fraction of your organization. This can provide some important advantages.
Conclusion
Here is quick summary:
- There is an important role for low code data science and no code machine learning and AI applications.
- They can be used to try out new ideas quickly and go from a concept to a simple model derived from data. Think of it as a “first look” or “Pre-POC” of a new idea.
- You should assume that your competitors and adversaries may be using no-code and low-code methods, which has consequences for your analytic strategy.
- It is a still a long journey to a full model and even a longer journey to a complete application that provides value and has an acceptable number of edge cases and failure modes. To obtain a competitive advantage, you need to: 1) develop a culture where those with ideas have access to no-code environments; and 2) develop efficient methods to move from no code machine learning / AI to POCs, prototypes, pilots and MVP. The first is relatively easy; the second is relatively hard.
References
[1] Marcus Woo. “The Rise of No/Low Code Software Development—No Experience Needed?.” Engineering (Beijing, China) 6, no. 9 (2020): 960. Available from PubMed Central PMC7361109.
[2] Robert L. Grossman. Developing an Analytic Strategy: A Primer, Open Data Press, 2020.
[3] Robert L. Grossman. How to Navigate the Challenging Journey from an AI Algorithm to an AI Product, February 15, 2021, Analytic Strategy blog.