The Regulatory Risks Posed by GDPR When Using Bidstream Data in Real Time Bidding (RTB)
In real time bidding (RTB), there is a 100 ms auction in which different advertisers bid against each other to place an ad on a webpage or other space offered by a publisher. This is why you sometimes have the experience when browsing that the web jumps a bit as you start to read the page. The jump is because the web page content can shift after the ad loads.
The data exchanged in this auction is called bidstream data and includes location information, information about the application and system you are using, and standardized codes developed by the Interactive Advertising Bureau (IAB). The information about the application and system you are using is enough for online device fingerprinting. The specificity in the IAB codes can be a bit shocking the first time you look at them. Here are some examples of IAB codes from the IAB Taxonomy:
ID 281 Interest | Businesses and Finance | Bankruptcy
ID 351 Interest | Family and Relationships | Adoption and Fostering
ID 357 Interest | Family and Relationships | Special needs Kids
ID 396 Interest | Health and Medical Services | Mental Health Services
ID 432 Interest | Hobbies & Interests | Scrapbooking |
ID 434 Interest | Hobbies & Interests | Beekeeping |
ID 565 Interest | Pharmaceuticals, Conditions, and Symptoms | STD |
ID 568 Interest | Pharmaceuticals, Conditions, and Symptoms | Substance Abuse |
ID 572 Interest | Pharmaceuticals, Conditions, and Symptoms | Cancer |
There has been concerns about the leakage of privacy information in bidstream data for sometime and the inadequacy of the pop-up consents that are suppose to give users some control.
Providing Consent for Bidstream Tracking Data
For those website that follow the European General Data Protection Regulation (GDPR), users are presented with a pop-up banner that asks for consent for the collection of tracking information. In general, websites use this information for both internal purposes and for targeted advertising, such as supplying information for bidstream auctions.
In 2018, IAM developed a “consent framework” called the Transparency and Consent Framework to standardize how advertisers and publishers could collect and store the required consent information. The information is passed around in a format standardized by the IAB called the TC consent string.
Changes in the Regulatory Framework for Using Bidstream Data
The Irish Council for Civil Liberties (ICCL) has brought a case under the GDPR claiming the the IAB Transparency and Consent Framework and its use with TC String in real time bidding does not provide adequate consent [1]. The actual 174 page court filing [2] provides a very detailed explanation of the bidstream data that is exposed and why it should be considered a data breach under GDPR. For a good overview of the ICCL case and its implications, see [3].
Upcoming Regulatory Changes and Your Analytic Strategy
As a result of the ICCL court case, there maybe changes in the regulations for using bidstream data and one of the challenges from an analytic strategy point of view is to have a plan to update your own strategy in anticipation of future regulatory changes.
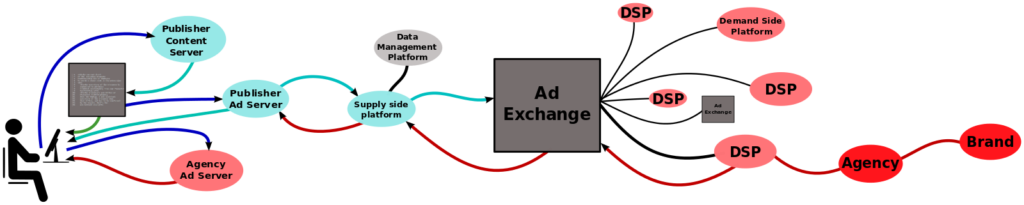
Problems with Bidstream Data
The exchange of bidstream data involves the advertiser, the publisher, the ad exchange, and, usually, a demand side and supply side platform. Advertisers buying space for advertising and publishers selling space for advertising are matched by the ad exchange. An advertiser can use a demand side platform to work with different networks of publishers and a publisher can use a supply side platform to work with different networks of advertisers. See Figure 2. With this many different entities involved in the auction, it is not surprising that there are often problems with bidstream data.
Inaccurate information. Given the amount of information exchanged with RTB and the monetary value involved, there is a significant level of inaccurate information being exchanged and a significant level of activity where the bidstream data is being used for purposes for which it was not intended and for which it was not consented. An example would be surveilling bidstream data and processing it using device fingerprints to create profiles of the users bidding.
Misuse of bidstream data. This is an example of adversarial analytics in the original sense (not the more modern GAN sense) in which there are two parties building analytic models that are at cross purposes. Here the advertisers and published exchanging bidstream information for real time auctions and the adversaries who are monitoring the information to build profiles of users that can be monetized.
Challenges with changing it. Most websites list a long list of advertising partners that they exchange bidstream data with it (often hundreds) and leave it to the user to update or correct the information for each partner. This is almost never practical.
The Emerging Era of Post Third Party Cookies
We are moving to an era in which advertising will not be able to use third party cookies, but rather rely on other types of information for matching advertisers and publishers. From an analytic strategy point of view, it is critical to make sure that your analytic frameworks still provide the value you require when third party cookies are not supported. More generally, platforms will have to update so as not to rely on third party cookies.
Regulatory changes almost always take years, giving your organization time to put in new place new analytic frameworks. The challenge though is usually not a technical one of transitioning to a new regulatory framework but rather figuring out how to extract the necessary business value in the new regulatory framework to provide the foundation for a successful analytic business.
References
[1] Irish Council for Civil Liberties, ICCL lawsuit takes aim at Google, Facebook, Amazon, Twitter and the entire online advertising industry, 15 June 2021, retrieved from ICCL.ie on December 6, 2021.
[2] ICCL complaint filed against IAB Technology Lab, Inc. and others in Hamburg District Court, May 15, 2021 (machine translated from the original German).
[3] Daniel Cooper, How a civil rights group is holding Europe’s online ad industry to account, Engadget, December 3, 2021. Retrieved from Engadget on Dec 14, 2021.