
The Hierarchy of Uncertainty and Why Models Break Down

In the news over the past month was the story of how the Ever Given blocked the Suez Canal and stopped an estimated 10% of global shipping and how the collapse of Archegos Capital Management led to billions of dollars of losses, including $2 billion of losses for Nomura, Japan’s largest bank, and $5 billion of losses from Credit Suisse, an investment banking company headquartered in Switzerland. Lloyd’s of London is expected to have losses of approximately $100 million from the delay to shipping that it insured.
Banks run multiple types of risk models to protect themselves from these types of events from happening, as do insurance companies. In this post, we examine some of the reasons that predictive models have trouble with these types of losses and what can be done about it. More generally, we look at the types of uncertainty that arise when building machine learning and AI models.
The Hierarchy of Unknowns in Machine learning
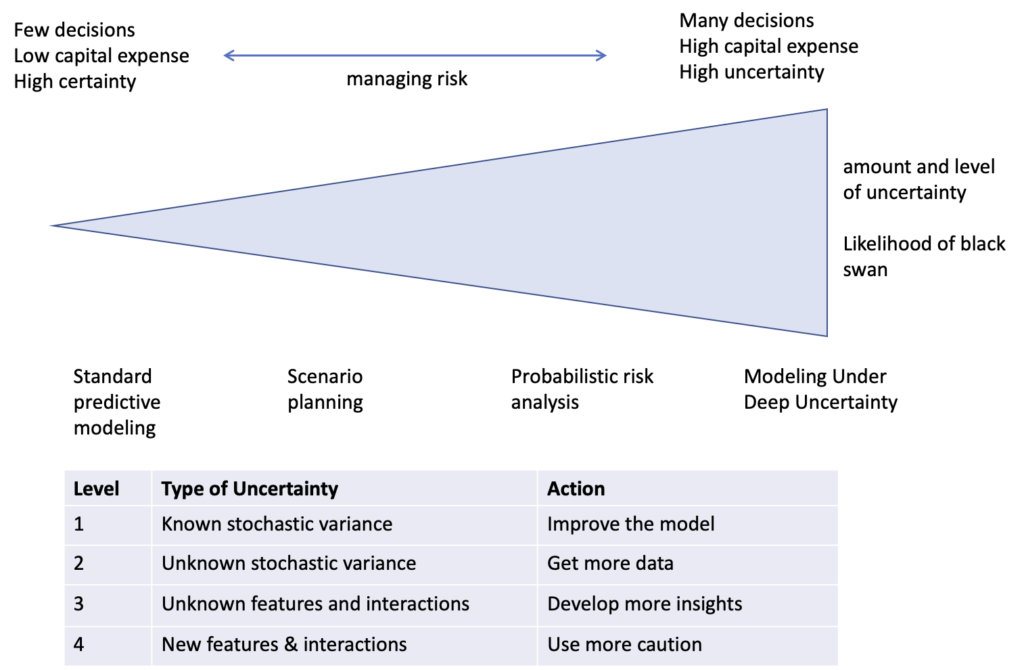
We assume that we have a predictive risk model that has inputs or features. It is quite helpful to distinguish between four types of unknowns and to view these as forming a hierarchy.
- Known stochastic variance. Stochastic here simply means that the inputs or features are not deterministic but instead vary and that the variances can be described by a probability distributions. This is the normal state of affairs for most models. These types of models have false positives and false negatives, but are the types of models that data scientists build routinely. One of the ways that these types of models can break down is through drift – over time the behavior that models attempt to capture tends to drift and models might be updated and re-estimated to capture this drift.
- Unknown stochastic variance. It’s common not to have enough data to be able to characterize the probability distributions of the variables driving your model. In this case, getting more data is critical. A particular challenge are long tailed distributions, or distributions associated with power laws, since this can create situations in which collecting enough data is particularly challenging. There are a number of specialized techniques used in this case, such as catastrophe modeling (“cat modeling“), which is used to predict catastrophic losses, such as losses associated with earthquakes or hurricanes.
- Unknown variables, features, actors and interactions. In practice, models are approximate and usually do not have all the relevant features. Overtime, as modelers understanding improves, additional features can be added to improve the performance of the model. These days this is often done by using large amounts of data and using deep learning to create features automatically. This is a very effective approach, but the larger the data, the more likely it is to be biased, which introduces biases into the model.
- New behavior, new interactions and actors. As container grew in size, they became large enough to block the canal, a new behavior. You can also think of this as an emergent behavior, since the size of ships has been increasing for a long time, but as the size increases past certain thresholds new types of behavior emerge, such as blocking a particular canal. As another example, one of the reasons that Archegos Capital collapse is the instability caused by a new type of complex financial instrument called a total return swap [2], which again you can think of a new type of behavior associated with a new type of financial instrument.
The Difference Between Level 2 and Level 3 Uncertainty
It’s standard in data science to distinguish between risk and uncertainty: You are dealing with risk when you know all the alternatives, outcomes and their probabilities (Level 1 uncertainty above). You are dealing with uncertainty when you do not know all the alternatives, outcomes or their probabilities (Level 2 or higher levels of uncertainty above).
The Difference Between Level 3 and Level 4 Uncertainty
There is a subtle but critical difference between Level 3 and Level 4 uncertainty. With Level 3 uncertainty, the features, actors, or interactions are present, but not yet understood and not yet included in the model. Once identified, there may, or may not, be enough data to accurately model their distribution (the difference between Level 1 and Level 2 variables and features). With Level 4 Uncertainty, new behavior appears, such as the use by investors of total return swaps, or the transportation of containers by ships so large that they can completely block a canal.
Black Swans
A black swan can be defined as an unpredictable or unforeseen event, typically one with extreme consequences. Black swan events were popularized by Nassim Talab in his influential book by that name [3]. The term “black swan” has been used since the second century to refer to something impossible or unlikely, since only white swans were seen by Europeans until a black swan was seen by Dutch explorers visiting Australia in 1697.
Black swans can arise from the behaviors 2, 3 and 4 in the hierarchy of uncertainty. For example, they can arise when tail events occur in Level 2 uncertainty, when behavior that is not yet identified occurs in Level 3 uncertainty, or when new behavior or actors arise in Level 4 uncertainty.
Talab has importantly pointed out the fragile and unstable state that often occurs due to new interactions that arise, such as the excessive risk taking by banks, the bursting of the housing bubble, and credit illiquidity that led to the 2007-2008 financial crisis [4].
Deep Uncertainty
Another way of thinking of the different types of uncertainty in the hierarchy of uncertainty is through the concept of deep uncertainty. One definition of deep uncertainty is [5]:
- Likelihood of future events & outcomes cannot be well-characterized with existing data and models
- Uncertainty cannot be reduced by gathering additional information
- Stakeholders disagree on consequences of actions
There is an emerging field called modeling under deep uncertainty (MUDU) which is establishing best practices for building models with deep uncertainty [5].
Best Practices
Figure 2 summarizes some best practices when faced with different types of uncertainty. With Level 1 uncertainty, simply improving the model helps, while re-estimating the model is necessary to manage drift. With Level 2 uncertainty, getting more data can help. It’s critical to understand whether the variable is long tailed and whether a power law is involved. If so, it may not be likely that you will get enough data before a black swan like event occurs. With Level 3 uncertainty, it’s more about gaining more insight into root causes, external interactions, the robustness of the system than improving the model. Finally, with Level 4 uncertainty, the best approach is to develop more caution and try to be quicker to detect new actors and new interactions and to take appropriate actions than your competitors.
References
[1] Container Ship ‘Ever Given’ stuck in the Suez Canal, Egypt – March 24th, 2021. Contains modified Copernicus Sentinel data [2021], processed by Pierre Markuse (License: Creative Commons Attribution 2.0 Generic)
[2] Quentin Webb, Alexander Osipovich and Peter Santilli, Wall Street Journal, March 30, 2021, What Is a Total Return Swap and How Did Archegos Capital Use It?
[3] Taleb, Nassim Nicholas. The black swan: The impact of the highly improbable. Vol. 2. Random house, 2007.
[4] Taleb, Nassim Nicholas. Antifragile: Things that gain from disorder. Vol. 3. Random House Incorporated, 2012.
[4] Walker, Warren E., Robert J. Lempert, and Jan H. Kwakkel. “Deep uncertainty.” Delft University of Technology 1, no. 2 (2012).