I have written about a post per month for the past two years about analytics and I thought it might be interesting to group these by categories and themes.
Theme 1: Running an algorithm over data is easy, building a useful AI-based system is quite hard
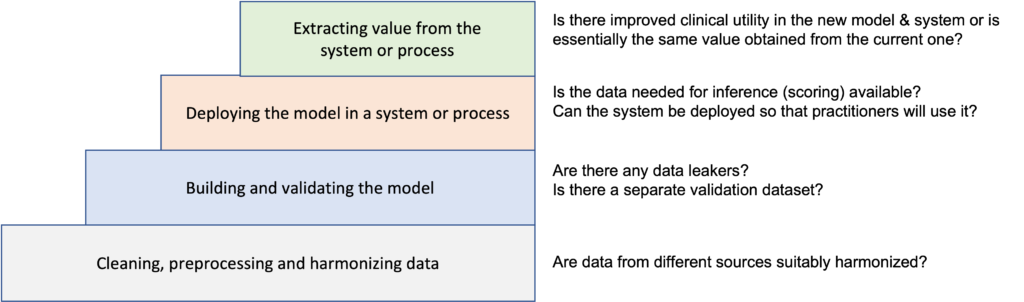
We train data scientists to transform data into rows and columns and then run an algorithm over the rectangular data, but as the articles below discuss, this is just one of many iterative steps in building a functional and useful AI-based system.
- Why Didn’t AI Contribute More to COVID-19 Research? (July 14, 2021)
- How to Navigate the Challenging Journey from an AI Algorithm to an AI Product (Feb 15, 2021)
- Why Great Machine Learning Models are Never Enough: Three lessons About Data Science from Dr. Foege’s Letter (Oct 12, 2020)
- Why Do So Many Analytic and AI Projects Fail? (May 11, 2020)
- Deploying Analytic Models (Nov 4, 2019)
Theme 2: AI/ML Business Models
Developing a successful business model is hard in general, and AI/ML business models are no exception. I was a bit surprised that there were not more articles in this theme (for three years, I taught a course at the University of Chicago Booth School of Business that discuss edAI/ML business models as one of its sections), and I intend to write more of these articles during the next two years.
- Machine Learning vs AI Business Models — What’s New with the Economics of AI? (Nov 12 2020)
- Starting a Lean Analytic Start-Up: Four Key Questions to Ask (June 12, 2020)
Theme 3: Organizational Issues About AI/ML
- Three Reasons All Corporate Boards Need Someone Who Understands Both Analytic Innovation and Analytic Strategy (Jan 14, 2021)
- Five Steps to Improve the Analytic Maturity of Your Company — 2021 Edition (Dec 14, 2020)
- Continuous Improvement, Innovation and Disruption in AI (July 6, 2020)
- Analytic governance and why it matters (April 10, 2020)
- Improving the Analytic Maturity Level of Your Company (Oct 2, 2019)
I also spent some time researching and writing mini profiles about some of the advocates for data driven decisions, analytics and systems. These include posts (in alphabetical) about
Theme 4: Profiles in AI/ML
- W. Edwards Demming (May 10, 2021)
- William H. Foege (Oct 12, 2020)
- Frank Knight (Mar 14, 2021)
- George Heilmeier (Dec 6, 2019)
Other Topics
I also wrote posts about the concept of a grand strategy in analytics and the challenges crossing the data chasm in analytics. Looking back, I was a bit surprised that I didn’t write more articles about analytic strategy per se, something I intend to rectify over the next two years.
Please contact me via the mail form if you would like me to write about anything specific in the future.