
Over the last several months, a number of reports and technical publications have appeared describing the lack of success applying machine learning and AI to COVID-19 research. Although many people are surprised, the readers of this blog should not be. Getting data is hard, understanding data is hard, building models is hard, embedding AI models in systems is hard, and extracting value from AI systems is hard. This is one of the themes of this blog and why there is a big difference between applying an AI algorithm to a dataset and developing a successful AI application.
BMJ review of 232 predictive models
If you haven’t seen any of these reports, a good place to start is the review article that appeared in the April, 2021 issue of BMJ and which analyzed 169 studies describing 232 COVID prediction models [1]. The title of the article “Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal” gives a good idea of what is covered. What the authors found is that of the 232 predictive models,
- “[the] models are poorly reported and at high risk of bias, raising concern that their predictions could be unreliable when applied in daily practice.”
- “Two prediction models (one for diagnosis and one for prognosis) were identified as being of higher quality than others and efforts should be made to validate these in other datasets.”
In other words, of the 232 predictive models studied, all except two could be unreliable when applied in clinical practice and the remaining two needed to be validated with data from additional datasets. This is not the good news, but it is not surprising either.
Turing Institute Report
The Alan Turing Institute is a UK research institute focused on data science and AI with the tag line “We believe data science and artificial intelligence will change the world.” (So do I, by the way, but I also believe that this data driven revolution has been going on for the past thirty years.) The Turing Institute ran a series of workshops on COVID-19 research and produced a summary report [2]. Here are some of the conclusions of the report:
- “… the single most consistent message across the workshops was the importance – and at times lack – of robust and timely data. Problems around data availability, access and standardisation spanned the entire spectrum of data science activity during the pandemic. The message was clear: better data would enable a better response.”
- “… conventional data analysis has been at the heart of the COVID-19 response, not AI”.
Perhaps most noteworthy is what the report didn’t say. It didn’t describe successful AI tools and their impact, but rather described challenges getting data, difficulties standardizing the data for analysis, and the many issues related around inequality and inclusion. It also described the “difficulty of communicating transparently with other researchers, policy makers and the public, particularly around issues of modelling and uncertainty [2].”
Don’t be Surprised When Black Box Frameworks Fail to Bring Value
Why should readers of this blog not be surprised? First, several of the posts of the themes of this blog is about 1) the difficulties getting data (Chapter 6, Crossing the Data Chasm of my Primer), building models, deploying models in AI systems, and extracting value from the AI systems, and 2) how to develop analytic strategies and implement best practices to overcome these difficulties. For example, my post “Why do so many analytic and AI projects fail” suggests using a simple radar plot to measure over time the increase or decrease int the likelihood that an AI project will fail.
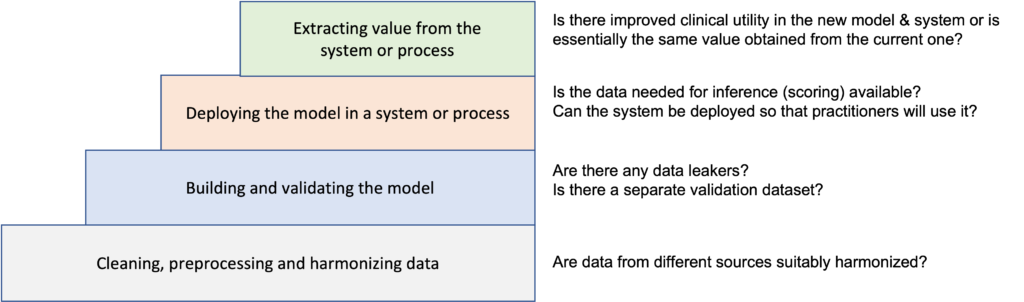
Today, we have good tools and software frameworks for building AI models, but it still requires a lot of work and a good understanding of the practice of analytics to build and deploy a useful AI system. As Figure 1 shows, one level of understanding comes from cleaning and preparing data modeling, another from building a model with the data, another from deploying the model, and a still higher level when you can extract value from the model. Even for skilled modelers, data leakage is always a problem and can be quite hard to track down. Often times, you do not understand how to clean, prepare and harmonize data appropriately until you have built a model. Similarly, it can be hard to determine what features are actually available for a model running in the field until you build and deploy your first system that uses the model. Almost always, you do not understand how to build the right model, deploy the model correctly, and create the right actions around the model’s output until you see the system performing in practice, understand what works and what doesn’t, and start again.
With deep learning frameworks such as PyTorch, Keras and TensorFlow, building models does not require features. You can take someone else’s data to use in transfer learning and someone else’s modeling software and treat both as blackboxes. With this approach, you shouldn’t surprised when the deployed model in the real world doesn’t bring value. The staircase of data understanding (Figure 1) is about the real world practice of analytics and the engineering of analytic systems, and most of what we teach these days are machine learning and AI algorithms over someone else’s data.
References
[1] Laure Wynants, Ben Van Calster, Gary S. Collins, Richard D. Riley, Georg Heinze, Ewoud Schuit, Marc MJ Bonten et al. “Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal.” British Medical Journal 369 (2020).
[2] Alan Turing Institute, Data science and AI in the age of COVID-19. Reflections on the response of the UK’s data science and AI community to the COVID-19 pandemic, retrieved from: www.turing.ac.uk (https://www.turing.ac.uk/research/publications/data-science-and-ai-age-covid-19-report) on July 2, 2021.