
Little languages. A key insight in the development of Unix was that there was an important role for what became known as little languages, which are simple specialized languages for executing important types of tasks. The insight was that it is much easier to design a little language that can be implemented efficiently for a specific task than a general language that is designed to support all tasks. For example, in Unix there are specialized little languages and corresponding programs for:
- pattern matching (regular expressions)
- text line editing (ed/sed)
- grammars for languages (lex/yacc)
- shell services (sh)
- text formatting (troff/nroff)
- processing data records (awk)
- processing data (S)
This point of view is explained clearly in an influential 1986 ACM article by Jon Bentley called Little Languages. Of course, on the downside is that software developers must learn the little languages.
How should we view models in analytics, AI and data science? From the viewpoint of the practice of analytics, it is important to understand the different perspectives that different members in your organization have about analytic models.
- If you are a modeler, your task is often given some data to develop an analytic model. So your input is data and your output is an analytic model. Historically, modelers split data into training and test (or validation), but these days with hyper-parameters it’s more common to split into training, dev and test datasets.
- If you are a member of an operations team (what I call analyticOps) that is deploying analytic models in products, services or internal operations, than you must manage multiple analytic models and make sure that they are processing data as required to produce scores and that the associated post-processing is in place to process the scores and take the required actions.
- If you are a member of the IT team, or the IT team deploying analytic models, such as the AIOps or ModelOps team, then you task is to take the models developed by the modeling team, manage them as enterprise IT assets, and deploy them as needed into the required products, services and internal processes.
- Finally, if you are developing an analytic strategy, then the models produced by the modeling team and the products, services and internal processes managed by the analytic operations team are part of a broader analytic ecosystem that might also include supply chain partners and product ecosystem partners that also use models that your organization develops.
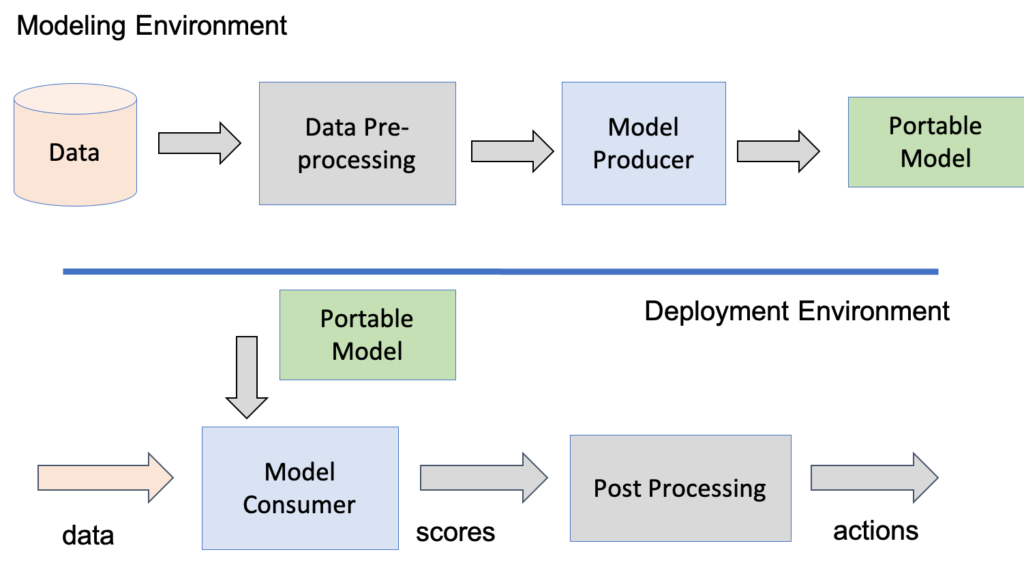
With this split (described in more detail in my post on the analytic diamond) and in my primer Developing an AI Strategy, a Primer, there is one team that produces models and one or more teams that consumes models, and so it is natural to ask what type of efficiencies can be obtained by using little languages for expressing models and using these little languages for managing models across an analytic enterprise and the analytic ecosystem that it supports, including all the applications and systems that produce models (model producers) and all the applications and systems that consume models (model consumers).
Analytic models as code. With the critical importance of DevOps, there is another important way to view models. With this view, models are simply code, and the way to manage code is with a version control system, continuous integration (CI), and continuous deployment (CD). Model code is dockerized in a container, and the dockerized container is managed with the same systems that are used for the CI/CD of the rest of the code. There are many more software developers than modelers, and so the most common way of viewing analytic models these days is as code.
Analytic models as described in little languages. Returning to the first point of view, there are several little languages that have been developed for analytic models:
- Predictive Model Markup Language (PMML). PMML is an XML language for expressing standard statistical, machine learning and data mining models, that has been used for over 20 years. It is widely deployed, and good at expressing the familiar machine learning models, such as decision trees, support vector machines and clusters, but does not support arbitrary models and has only a limited ability to support the data transformations that are needed for preparing features for models.
- Open Neural Network Exchange (ONNX). ONNX is a language for expressing deep learning neural network models and is supported by major systems for deep learning including TensorFlow, PyTorch and Keras. It is by far the most common language for expressing deep neural networks, but does not support standard statistical and data mining models as well, and also does not fully support data transformations that are often required in machine learning and analytics.
- Portable Format for Analytics (PFA). The Portable Format for Analytics is a newer little language and model interchange format for analytic models based upon JSON that is designed for the safe and secure execution of arbitrary analytic models and arbitrary data transformation. You can find an overview of PFA that was presented at KDD 2016 that also describes an open source PFA scoring engine. PFA supports the safe and secure execution of models in several ways, including:
- PFA models are strictly sandboxed
- PFA models can only access data that is explicitly given to it
- PFA models cannot manipulate anything beyond its own state
- PFA models have no way to access the disk, network or operating system
- PFA models have static data types and missing value safety
- Combinations of little languages. In some situations, it might make sense to complement ONNX with PFA to support the data transformation not available, or not available efficiently in ONNX, and to support models that are not available in ONNX.
When you need to deploy models safely. There are some situations when it is critical to deploy code safely. It is well known that changing just a single line of code can bring down an enterprise system and for this reason there is always a risk in deploying analytic models as code in system that requires high availability with accurate results. As another example, when analytic models are deployed at the edges, including IoT, OT and in consumer devices, there are strong arguments for deploying models in safe languages, such as PFA, or other small languages designed for this purpose.
References
[1] Bentley J. Programming pearls: little languages. Communications of the ACM. 1986 Aug 1;29(8):711-21.
[2] Pivarski J, Bennett C, Grossman RL. Deploying analytics with the portable format for analytics (PFA). In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2016 Aug 13 (pp. 579-588).