
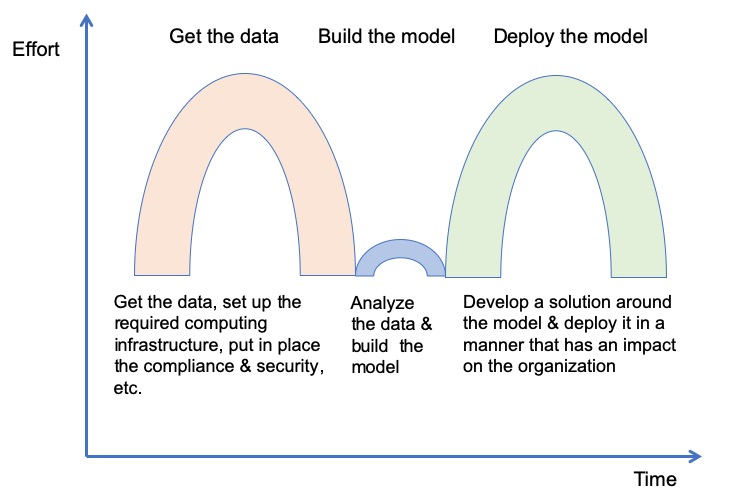
One of my defining experiences in analytics occurred over twenty years ago in 1998. At that time, it was very challenging to build analytic models if the data did not fit into the memory of a single computer. This was the time that clusters of distributed computers (called Beowulf clusters then) were still new and only used in academia, ensembles of models were still largely unknown, and when Python and R were still only used by a few fringe communities. I was working at a venture backed start up that developed software for building trees and other common analytic models over clusters of workstations by using ensembles of models. One of our first customers gave us clean, nicely labeled data just when they said they would (in over twenty years this has only happened a handful of times). We built a model that outperformed what was used in production and I (very) naively thought we were done. Little did I understand just how much work it would be to get the model into production and how much it would have to change to get it there. The figure above gives the general idea, but in practice getting the data and deploying the model is even harder than the figure indicates.
Most analytic and machine learning conferences even today focus on new algorithms and new software but very little on deploying analytic models. An exception is the workshop called “Common Model Infrastructure” which was held at KDD 2018 and ICDM 2019. The workshop describes its focus as “infrastructure for model lifecycle management—to support discovery, sharing, reuse, and reproducibility of machine learning, data mining, and data analytics models.”
I spoke at the CMI 2018 workshop at KDD 2018. My slides are on SlideShare and you can find them here. I singled out the following best practices:
Five Best Practices When Deploying Models
- Mature analytic organizations have an environment to automate testing and deployment of analytic models.
- Don’t think just about deploying analytic models, but make sure that you have a process for deploying analytic workflows.
- Focus not just on reducing Type 1 and Type 2 errors, but also data input errors, data quality errors, software errors, systems errors and human errors. People only remember that model didn’t work, not whose fault it was.
- Track value obtained by the deployed analytic model, even if it is not your explicit responsibility.
- It is often easier to increase the value of deployed model by improving the pre- and post- processing vs chasing smaller improvements in the model’s lift curve.
During the talk, I identified five common approaches for deploying analytic models. I remember these with the acronym E3RW:
- Embed analytics in databases
- Export models and deploy them by importing into scoring engines
- Encapsulate models using containers or virtual machines
- Read a table of values that provide the parameters of the model
- Wrap the code, workflow, or analytic system, and, perhaps, create a service
Although these days, with the popularity of continuous integration (CI) and continuous deployment (CD), encapsulating models in containers and using CI/CD tools is the approach du jour, each approach has its place.
I also identified five common mistakes when deploying analytic models.
Five Common Mistakes When Deploying Models
- Not understanding all the subtle differences between the supplied run time data used to train the model and the actual run time data the model sees.
- Thinking that the features are fixed and all that you will need to do is update the parameters.
- Thinking the model is done and not realizing how much work is required to keep up to date all the the pre- and post-processing required.
- Not checking in production to see if the inputs to the models drift slowly over time.
- Not checking that the model will keep running despite missing values, garbage values, etc. (even values that should never be missing in first place).
Copyright 2019 Robert L. Grossman